
摘要
在法律场景中,大模型最重要的问题不是能否生成流畅文本,而是能否基于真实、有效、可追溯的法律依据作答。RAG,即检索增强生成,是法律行业应用大模型的基础能力。本文系统分析法律 RAG 的建设思路,包括知识源选择、混合检索、文档结构化、引用机制、权限控制和质量评测,并指出法律 RAG 不能替代专业判断,而应成为律师和法务的可信知识基础设施。
正文
法律行业使用大模型时,最常见的风险是“看起来正确但实际错误”。模型可能编造不存在的案例,误引已经失效的法规,混淆不同地域的裁判规则,或者把一般商业判断包装成法律结论。这类问题在普通文本生成场景中可能只是质量瑕疵,但在法律场景中可能导致重大执业风险。因此,法律行业不能把大模型本身当作权威知识来源,而必须通过 RAG 建立可验证的知识基础。
RAG 的基本思路:是在模型回答之前,先从指定知识库中检索相关材料,再要求模型基于检索结果生成答案。对于法律行业而言,RAG 的关键不只是“多查资料”,而是确保资料来源可信、效力明确、权限合规、引用准确、结论可追溯。换言之,法律 RAG 的目标不是让模型“知道更多”,而是让模型“只能根据被授权、被验证、被引用的材料回答”。

法律 RAG 的第一项工作是建设高质量知识源。知识源通常可以分为三类:
- 第一类是外部权威法律资料,包括法律法规、司法解释、部门规章、监管规则、指导案例、裁判文书、行政处罚、交易所规则和行业指引。
- 第二类是机构内部知识,包括法律意见书、研究备忘录、合同模板、条款库、审查清单、项目复盘、客户行业研究和过往谈判经验。
- 第三类是项目或案件资料,包括合同、邮件、会议纪要、证据材料、尽调文件、监管函件和客户提供的事实材料。
这三类知识源在使用方式上应当严格区分。外部法律资料更强调权威性、时效性和适用地域;内部知识更强调经验复用、风格一致和权限控制;项目资料则更强调事实准确、版本管理和客户隔离。如果将三类材料混在一起,不加标注地交给模型处理,就很容易出现来源混淆。例如,模型可能把某个项目中的谈判立场当成通用法律规则,或者把某份旧版本合同当成最终签署文本。
法律 RAG 的第二项关键工作是文档结构化。法律文档通常有复杂层级,例如法律法规有章、节、条、款、项,合同有章节、条款、定义和附件,裁判文书有事实、争议焦点、法院认为和裁判结果。如果简单按固定字数切分文档,可能破坏语义结构,导致检索结果缺失上下文。更合理的做法是按照法律文本的自然结构进行切分,并为每个片段添加元数据,例如文件名称、版本号、生效日期、失效日期、发布机关、法院层级、案件类型、合同类型、客户、项目编号和访问权限。
第三项工作是建立混合检索机制。法律问题往往既需要精确匹配,也需要语义理解。比如查找某个法条编号、案号、合同第 12.3 条,应依赖关键词检索;查找类似裁判观点、相近条款风险、同类交易安排,则需要向量检索;判断法规是否现行有效,需要元数据过滤;分析法条与案例之间的关系,则可能需要知识图谱。成熟的法律 RAG 系统通常不应只依赖单一向量检索,而应结合关键词检索、语义检索、元数据过滤、重排序和权威性排序。
第四项工作是强制引用机制。法律 RAG 的输出不能只是“结论式回答”,而应包含依据链。一个合格的法律 AI 回答,至少应区分事实依据、法律依据、案例依据、内部规则和模型推断。对于每一个重要结论,系统都应返回对应的来源片段,并尽可能显示原文、出处和版本信息。例如,在合同审查中,如果系统提示“违约责任上限缺失”,就应指出对应合同条款;如果建议增加责任上限,则应说明该建议来自内部审查 playbook、历史模板,还是律师自定义规则。
第五项工作是权限和保密控制。法律数据通常高度敏感,尤其是律所的不同客户、不同案件、不同项目之间,必须严格隔离。企业法务也需要区分普通业务人员、法务人员、管理层、外部律师等不同访问权限。因此,法律 RAG 系统不能只做技术上的知识检索,还必须嵌入权限体系。用户只能检索其有权访问的材料,模型回答也不能泄露无权访问的信息。所有检索、生成、下载和引用行为都应留痕,便于事后审计。
第六项工作是质量评测。法律 RAG 的效果不能只看回答是否流畅,而要看是否准确、完整、可复核。评测指标可以包括:是否检索到正确法规或条款,引用是否真实,结论是否与依据匹配,是否遗漏关键风险,是否混淆不同法律领域,是否错误使用过期材料,是否越权访问,是否存在无依据推断。对于高风险场景,还应建立人工抽检和持续反馈机制,将错误样本反向用于优化检索、切分、提示词和知识库治理。
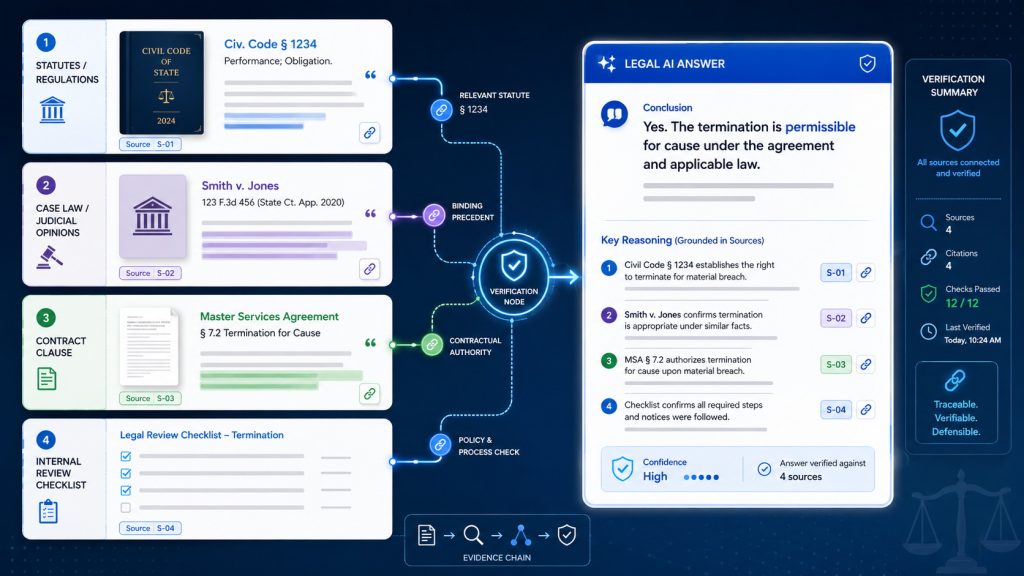
需要强调的是,RAG 并不能完全消除法律 AI 的风险。检索结果可能不完整,知识库可能未及时更新,模型可能误解材料含义,用户问题也可能缺少关键事实。因此,法律 RAG 应始终保留不确定性表达。当资料不足、法律规则存在争议、事实条件不明或不同法院观点不一致时,系统应明确提示“无法形成确定结论”或“需要律师进一步判断”,而不是强行给出确定答案。
从落地顺序看,法律机构可以先从内部知识库 RAG 入手。原因是内部知识边界相对清楚,业务价值明显,且更容易控制质量。例如,先把合同模板、审查清单、常见问题、过往研究备忘录和项目复盘纳入知识库,让律师和法务能够快速检索组织经验。随后再接入外部法规案例库,并针对特定业务领域建设专业化 RAG,例如劳动用工、数据合规、投融资、知识产权或金融监管。
最终,法律 RAG 的价值不在于制造一个“万能法律问答机器人”,而在于建设一套可信知识基础设施。它让法律机构的知识从分散文件变成可调用资产,让律师从重复检索中释放出来,让法务团队能够更一致地响应业务问题,也让大模型的输出具备可追溯、可复核和可治理的基础。对于法律行业而言,RAG 不是可选功能,而是大模型进入严肃业务场景的必要前提。


 京公网安备 11010802034617号
京公网安备 11010802034617号